[4장에서 배울것]
- 카프카의 리플리케이션 동작
- 리더와 팔로워의 역할
- 리더에포크와 복구 동작
- 리플리케이션 동작과 관련 있는 "컨트롤러, 컨트롤러의 동작"
- 로그와 로그 컴팩션
1. 카프카 리플리케이션
메인 허브의 역할을 하는 카프카 클러스터가 정상적으로 동작하지 못하면 매우 심각한 문제가 생길 수 있다.
따라서 카프카는 초기 설계단계부터 안정적인 서비스를 운영할 수 있도록 "리플리케이션"이라는 동작을 함.
1) 리플리케이션 동작 개요
- 카프카는 브로커의 장애에도 불구하고 연속적으로 안정적인 서비스 제공함으로써 데이터 유실을 방지하고 유연성을 제공한다.
- 토픽 생성 시 아래와 같이 "replicaion factor"라는 옵션을 설정해야 한다.
- 생성 후 describe 명령어로 상세보기 실행
> --create --topic peter-test01 --partitions 1 --replication-factor 3
[출력]
Create topic peter-test01
> --bootstrap-server peter-kafka01.foo.bar:9092 --topic peter--test01 --describe
[출력]
Topic: peter-test01 PartitionCount: 1 ReplicationFactor: 3 Configs : segment.bytes=1073741824
Topic: peter-test01 Partition : 0 Leader 1 Replicas :1,2,3 Isr : 1,2,3PartitionCount :1 <- 토픽의 파티션 수 1
ReplicationFactor : 3 <- 리플리케이션 팩터 수 3
Partition : 0 Leader : 1 Replicas : 1,2,3 Isr : 1,2,3
<- 리더는 브로커 1을 나타낸다. 리플리케이션들은 브로커 1,2,3에 있고 현대 동기화 하고 있는 리플리케이션들은 브로커 1,2,3이라는 의미이다. Isr(InSyncReplica) :
peter-test01 토픽으로 "test message1"이라는 메시지를 전송하고 세그먼트 파일의 내용을 확인하면, 3대의 브로커가 동일한 메시지를 가지고 있는 것을 알 수 있다.
replication factor이라는 옵션을 이용해 관리자가 지정한 수만큼 리플리케이션을 가질 수 있어 N개의 리플리케이션이 있는 경우 N-1까지의 브로커 장애가 발생해도 메시지 손실 없이 안정적으로 주고받을 수 있다.
일반적으로 3개의 리플리케이션을 권장한다고 한다.
2) 리더와 팔로워
# 파티션의 리더와 팔로워란 무엇인지 알아보겠습니다.
- 파티션의 leader라는 부분은 리플리케이션 중 하나가 선정되며, 모든 읽기와 쓰기가 그 리더를 통해서만 가능하다.
- 프로듀서는 리플리케이션에게 메시지를 보내는 것이 아니라 리더에게만 메시지 전송, 컨슈머는 리더로부터 메시지를 가져옴.
- 프로듀서가 peter-test01 토픽으로 메시지를 전송하고, 파티션의 리더만 읽고 쓰기가 가능하므로 리더에게 메시지 전송, 컨슈머 동작에서도 0번 파티션의 리더에게만 메시지를 받음.
- 이때 팔로워들은 대기하는 것이 아닌, 리더에 문제가 발생하거나 이슈가 있을 경우를 대비해 언제든지 새로운 리더가 될 준비를 한다.
- 팔로워는 파티션의 리더가 새로운 메시지를 받았는지 확인하고, 새로운 메시지가 있다면 해당 메시지를 리더로부터 복제한다.

3) 복제 유지와 커밋
# 리더와 팔로워 간 복제 동작이 어떻게 이루어지는지 알아보겠습니다.
- 리더와 팔로워는 ISR(InSynReplica)라는 논리적 그룹에 묶여있음. 여기에 속한 팔로워만 새로운 리더의 자격을 가짐
- ISR 내의 팔로워들은 리더와의 데이터 일치를 유지하기 위해 지속적으로 리더의 데이터를 따라가게 되고, 리더는 ISR 내 모든 팔로워가 메시지를 받을 때까지 기다린다. 하지만 오류가 발생해서 리더로부터 데이터를 못 받는 경우가 있을 수 있다. 이때 이 팔로워에게 리더를 넘겨주면 메시지 손실이 발생할 수 있다.
# 리더는 읽고 쓰는 동작 말고도, 팔로워가 리플리케이션 동작을 잘 수행하는지 판단한다.
팔로워가 특정 주기 시간만큼 복제 요청을 하지 않는다?
=> 해당 팔로워 문제가 발생했다 판단해 ISR 그룹에서 추방
- 앞서 했던 describe 명령어를 통해 ISR목록을 확인하여 상태 점검을 할 수 있음.
ISR내에서 모든 팔로워의 복제가 완료되면 리더에서 "커밋" 표시를 해준다. (리플케이션 모두 메시지를 저장)
마지막 커밋 오프셋 위치는 "하이워터마크(high water mark)"라고 부른다.
메시지의 일관성을 위하여 커밋된 메시지만 컨슈머가 읽을 수 있다.
<커밋되지 않은 메시지를 컨슈머가 읽을 수 있게 허용하면 메시지 정합성이 깨짐>
=> 커밋된 메시지만 컨슈머가 읽어 갈 수 있다.

# 커밋되기 전 메시지를 컨슈머가 읽을 수 있다면?

# 각기 다른 컨슈머가 메시지를 컨슘하는 동안 파티션의 리더 선출이 발생하는 경우
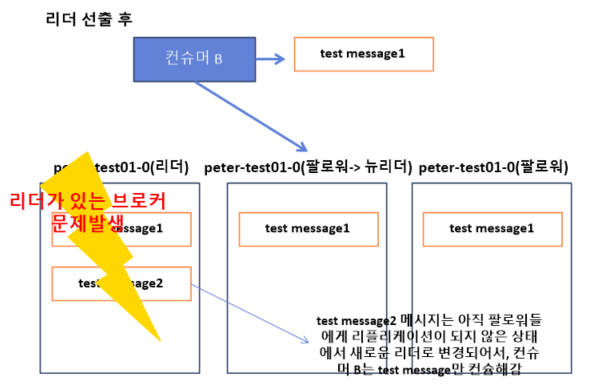
=> 커밋되지 않은 메시지를 컨슈머가 읽을 수 있게 허용한다면 동일한 토픽의 파티션에서 컨슘했음에도 메시지가 일치하지 않는 현상이 발생할 수 있다. 따라서, 커밋된 메시지만 컨슈머가 읽도록 구현됨!.
커밋된 위치가 중요하다.
- 커밋된 위치 알 수 있는 법?
모든 브로커가 재시작될 때, 커밋된 메시지를 유지하기 위해 로컬디스크의 "replication-offset-checkpoint"라는 파일에 마지막 커밋 오프셋 위치를 저장한다.
이 파일의 내용을 확인하고 리플리케이션되고 있는 다른 브로커들과 비교해 살펴보면, 어떤 브로커, 토픽, 파티션에 문제가 있는지 파악 가능.
=> 5) 리더에포크 과정을 통해 복구과정에 대해서 알 수 있음.
4) 리더와 팔로워의 단계별 리플리케이션 동작
앞서 본 것처럼 "리더"는 수많은 메시지를 읽고 쓰고, 팔로워의 리플리케이션 동작을 감시하며 매우 바쁘게 동작한다.
리더가 리플리케이션 동작을 위해 팔로워들과 많은 통신을 주고받거나 리플리케이션 동작에 많은 관여를 하면, 결과적으로 리더의 성능이 떨어져 카프카의 장점인 빠른 성능을 내기 어려워짐.
=> 리더 팔로워 간의 리플리케이션 동작을 처리할 때 서로의 통신을 최소화하도록 설계하여 리더의 부하를 줄였다.

현 상태는 리더는 모든 팔로워가 0번 오프셋 메시지를 리플리케이션하기 위한 요청을 보냈다는 사실을 알고 있다.
하지만 리더는 팔로워들이 0번 오프셋에 대한 리플리케이션 동작을 성공했는지에 대한 여부는 모른다.
# 그럼 어떻게 리더는 팔로워들의 리플리케이션 동작의 성공을 알 수 있을까?
# RabitMQ는 Ack를 통해 메시지 받았는지 알 수 있으나 카프카는 이런 Ack를 없앰으로써 리플리케이션 동작의 성능을 높였다.
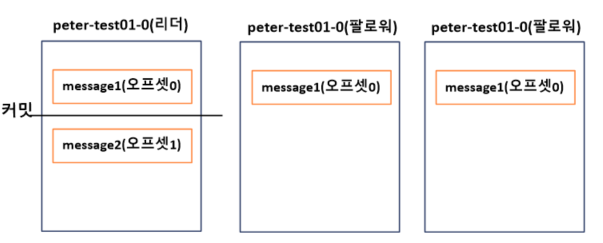
리더는 1번 오프셋의 위치에 새로운 메시지 message2를 프로듀서로부터 받은 뒤 저장한다.
0번 오프셋에 대한 리플리케이션 동작을 마친 팔로워 들을 리더에게 1번 오프셋에 대한 리플리케이션을 요청한다.
팔로워들로부터 1번 오프셋에 대한 리플리케이션 요청을 받은 리더는 팔로워들의 0번 오프셋에 대한 리플리케이션 동작을 성공했음을 인지하고, 오프셋 0에 대한 커밋 표시를 한 후 하이워터마크를 증가시킨다.
팔로워가 0번 오프셋에 대한 리플리케이션을 성공하지 못했다면, 팔로워는 1번 오프셋에 대한 리플리케이션 요청이 아닌 0번 오프셋에 대한 리플리케이션 요청을 보내게 된다.
따라서 리더는 팔로워들이 보내는 리플리케이션 요청의 오프셋을 보고, 팔로워들이 어느 위치의 오프셋까지 리플리케이션을 성공했는지 인지할 수 있다.
팔로워들로부터 1번 오프셋 메시지에 대한 리플리케이션 요청을 받은 리더는 응답에 0번 오프셋 message1 메시지가 커밋되었다는 내용도 함께 전달한다.
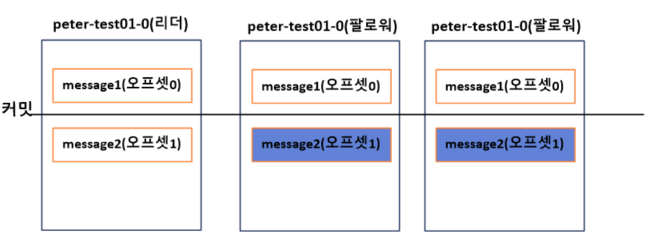
리더의 응답을 받은 모든 팔로워는 0번 오프셋 메시지가 커밋되었다는 사실을 인지하게 되고, 리더와 동일하게 커밋을 표시한다. 그리고 1번 오프셋 메시지인 message2를 리플리케이션한다.
이렇게, 리더와 팔로워는 일련의 과정을 반복하여 동일한 파티션 내에서 리더와 팔로워 간 메시지의 최신 상태를 유지한다.
카프카는 대량의 메시지를 처리하려는 목적을 가진 애플리케이션이기 때문에 RabbitMQ와 같은 메시징 시스템의 ACK를 통해 통신하는 방식은 성능상의 문제가 발생할 수 있다.
따라서 카프카는 이런 통신방식을 제외하였는데 이는 메시지를 주고받는 기능에 집중한다는 장점이 있다.
또한 리더와 팔로워 간의 리플리케이션 동작이 매우 빠르면서 신뢰할 수 있다는 장점이 있다.
카프카에서 리더가 푸시하는 방식이 아니라 팔로워가 풀하는 방식으로 동작하므로, 리더의 부하를 덜어주기 때문이다.
장점 : 성능이 좋고 신뢰할 수 있다!
5) 리더에포크와 복구
리더에포크
- 카프카의 파티션들이 복구 동작을 할때 메시지의 일관성을 유지하기 위한 용도로 이용됨.
- 컨트롤러에 의해 관리되는 32비트의 숫자로 표기됨.
- 리더에포크 정보는 리플리케이션 프로토콜에 의해 전파되고, 새로운 리더가 변경된 후 변경된 리더에 대한 정보는 팔로워에게 전달됨.
- 리더에포크는 보구 동작시 하이워타마크를 대체하는 수단으로 활용됨.
(1) 리더에포크 사용 X
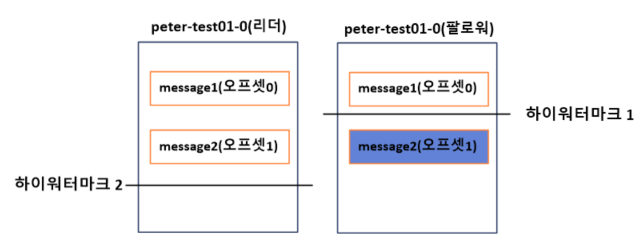
# 리더에포크가 없다는 가정하에 장애복구 과정
1. 리더 : message1 메시지 수신, 0번 오프셋에 저장, 팔로워는 0번 오프셋 가져오기 요청
2. 가져오기 요청을 통해 팔로워는 message1 메시지를 리더로부터 리플리케이션함.
3. 리더는 하이워터마크를 1로 올림
4. 리더는 프로듀서로부터 다음 메시지인 message2를 받은 뒤 1번 오프셋에 저장한다.
5. 팔로워는 다음 메시지인 message에 대해 리더에게 fetch, 응답으로 리더의 하이워터마크 변화를 감지하고 자신의 하이워터마크 1로 올림.
6. 팔로워는 1번 오프셋의 message2 메시지를 리더로 부터 리플리케이션함.
7. 팔로워는 2번 오프셋에 대한 요청을 리더에게 보내고, 요청을 받은 리더는 하이워터마크를 2로 올린다.
8. 팔로워는 2번 오프셋인 message2 메시지까지 리플리케이션을 완료했지만 아직 리더로부터 하이워터마크를 2로 올리는 내용 전달받지 못함
9. 팔로워가 다운됨.
장애에서 복구된 팔로워는 카프카 프로세스가 시작되면서 내부적으로 메시지 복구 동작을 한다.

1. 팔로워는 자신이 갖고 있는 메시지들 중에서 자신의 워터마크보다 높은 메시지들을 신뢰할 수 없는 메시지라 판단하고 삭제한다. 따라서 1번 오프셋의 message2는 삭제된다.
2. 팔로워는 리더에게 1번 오프셋의 새로운 메시지에 대한 가져오기 요청을 한다.
3. 이 순간 리더였던 브로커가 장애로 다운되면서, 유일한 팔로워가 리더로 승격됨.
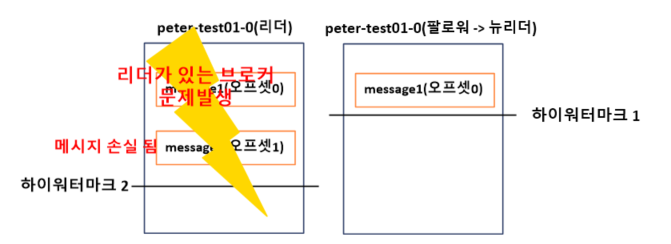
=> message2가 손실되었다.
(2) 리더에포크 사용 O
# 리더에포크를 사용하면 어떤차이가 있는지 알아보고 왜 써야되는지 보자!
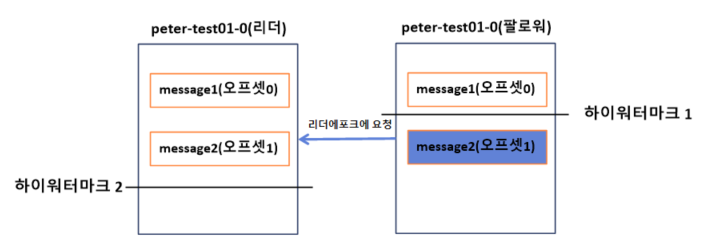
리더에포크를 사용하지 않는 경우에는 카프카 프로세스가 시작되면서 복구 동작을 통해 자신의 워터마크 보다 높은 메시지를 즉각 삭제했다. 하지만 리더에포크를 사용하는 경우에는 하이워터마크보다 앞에 있는 메시지를 무조건 삭제하는 것이 아니라 리더에게 리더에포크 요청을 보낸다.
1. 팔로워는 복구 동작을 하면서 리더에게 리더에포크 요청을 보냄
2. 요청을 받은 리더는 리더에포크의 응답으로 1번 오프셋의 message2까지 라고 팔로워에게 보낸다.
3. 팔로워는 자신의 하이워터마크보다 높은 1번 오프셋의 message2를 삭제하지 않고, 리더의 응답을 확인한 후 message2까지 자신의 하이워터마크를 상향조정한다.
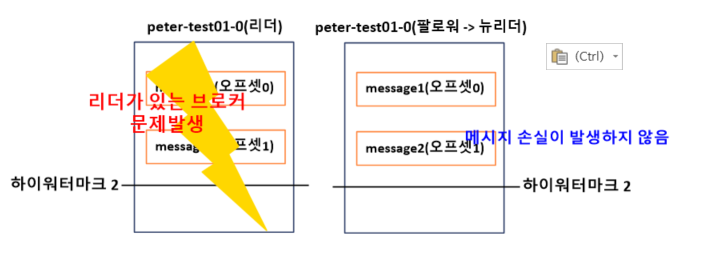
=> 리더에포크 요청과 응답 과정을 통해 팔로워의 하이워터마크를 올릴 수 있었고 메시지 손실이 발생하지 않음.
2. 컨트롤러
컨트롤러
- 리더 선출을 맡음 (파티션의 ISR 리스트 중에서 리더를 선출함)
- 카프카 클러스터 중 하나의 브로커가 컨트롤러 역할을 함.
- ISR 리스트정보 : 주키퍼에 저장됨.
- 컨트롤러는 브로커가 실패하는 것을 감시함, 실패가 감지되면 즉시 ISR 리스트 중 하나를 새로운 파티션 리더로 선출함.
- 선출된 리더의 정보는 주키퍼에 기록하고, 변경된 정보를 모든 브로커에게 전달한다.
리더가 다운되면, 해당 파티션으로 읽기 쓰기가 불가능해고 클라이언트에 설정되어 있는 재시도 숫자만큼 재시도를 한다. 따라서 리더 선출 작업이 빠르게 이뤄져야 한다.
# 참조) 카프카 버전 1.1.0 부터 리더 선출 작업 속도가 빨라짐 (불필요한 로깅 없애고, 주키퍼 비동기 API를 반영함)
A big part of the improvement comes from fixing a logging overhead, which unnecessarily logs all partitions in the cluster every time the leader of a single partition changes. By just fixing the logging overhead, the controlled shutdown time was reduced from 6.5 minutes to 30 seconds. The asynchronous ZooKeeper API change reduced this time further to 3 seconds. These improvements significantly reduce the time to restart a Kafka cluster.
(https://www.confluent.io/blog/apache-kafka-supports-200k-partitions-per-cluster/)
Apache Kafka Supports 200K Partitions Per Cluster | Confluent
Since the Apache Kafka® 1.1.0 release, there has been a significant increase in the number of partitions that a single Kafka cluster can support from the deployment and the availability perspective.
www.confluent.io
3. 로그(로그 세그먼트)
카프카의 토픽으로 들어오는 메시지(레코드)는 세그먼트(로그 세그먼트)라는 파일에 저장된다.
메시지는 정해진 형식에 맞추어 순차적으로 로그 세그먼트 파일에 저장된다.
로그 세그먼트에는 메시지의 내용만 저장되는 것이 아니라 메시지의 키, 밸류, 오프셋, 메시지 크기 같은 정보가 함께 저장되며, 로그 세그먼트 파일들은 브로커의 로컬 디스크에 보관된다.
하나의 로그 세그먼트 크기가 너무 커져버리면 파일 관리가 어려워져, 1GB를 기본값으로 설정함. 이보다 커지면 "롤링전략"을 적용한다. 이는 로그세그먼트에 카프카로 들어오는 메시지들을 계속 덧붙이다가 1GB에 도달하면 해당 세그먼트 파일을 닫고 새로운 세그먼트 파일을 생성하는 방식으로 진행된다.
이렇게 롤링전략이 준비되어 있찌만, 세그먼트 파일이 무한히 늘어날 경우를 대비해 관리계획을 수립해야되는데
크게 "로그 세그먼트 삭제"와 "로그 세그먼트 컴팩션" 기법이 있다.
이제부터 로그 세그먼트 관리기법 두 방법에 대해서 알아보겠다.
1) 로그 세그먼트 삭제
- 브로커 설정 파일인 server.properties에서 log.cleanup.policy가 delet로 명시 되어야 함. (기본값)
카프카 관리자는 토픽마다 보관주기를 조정해서, 얼마만큼의 기간 동안 카프카에 로그를 저장할지를 결정하고 관리할 수 있다.
- 관리자가 별도의 retention.ms 옵션을 설정하지 않으면 server.properties에 적용된 옵션값이 적용된다.
- default가 7일이므로, 모든 세그먼트 파일을 7일이 지나면 전부 삭제됨.
- retention.bytes라는 옵션으로 크기 기준으로 로그세그먼트 삭제도 가능.
2) 로그 세그먼트 컴팩션
로그를 삭제하지 않고 컴팩션하여 보관한다.
로그 컴팩션은 기본적으로 로컬 디스크에 저장되어 있는 세그먼트를 대상으로 실행되는데, 현재 활성화된 세그먼트는 제외하고 나머지 세그먼트들을 대상으로 컴팩션이 실행된다.
컴팩션 해도 로그를 무기한 보관하면 용량의 한계에 도달할 것이므로 단순하게 메시지를 컴팩션하기 보다는 효율적인 방식을 고안한다.
=> 카프카에서 로그 세그먼트를 컴팩션하면 메시지의 키값을 기준으로 마지막 데이터만 보관한다.
__cosumer_offset토픽 :
카프카의 내부 토픽, 컨슈머 그룹의 정보를 저장하는 토픽이다.
컨슈머 그룹이 어디까지 읽었는지를 나타내는 오프셋 커밋정보가 키와 밸류 형태로 저장된다.
로그 컴팩션은 메시지의 키값을 기준으로 과거 정보는 중요하지 않고 가장 마지막 값이 필요한 경우 사용한다.
예를 들어 구매 현황 상태를 보여주는 시스템에서 로그 컴팩션을 사용한다.
주문완료 -> 배송 준비 -> 배송중 -> 배송완료 , 이 4단계에서 구매한 사용자 아이디(메시지의 키)를 기준으로 최종상태(메시지의 밸류)만 사용자에게 노출하면 되므로 로그 컴팩션 기능을 사용할 수 있다.
# default가 키가 필수값이 아니므로 키를 필수값으로 전송해야 한다.
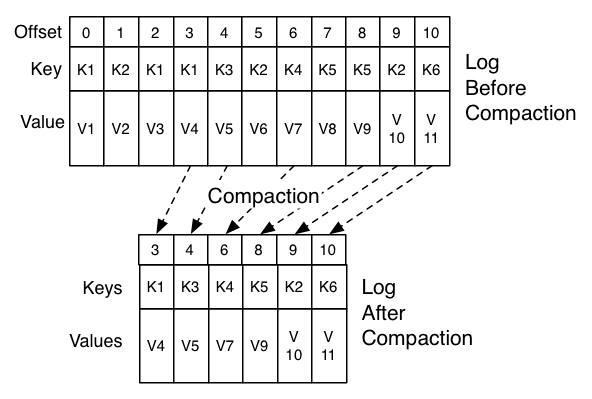
로그 컴팩션의 장점
- 빠른 장애복구 : 전체 로그를 복구하지 않고 메시지의 키를 기준으로 최신의 상태만 복구하므로 복구시간을 줄일 수 있다.
하지만, 모든 토픽에 로그 컴팩션을 적용하는것은 좋지 않다. 키값을 기준으로 최종값만 필요한 워크로드에 적용하는 것이 바람직한다. 로그 컴팩션 작업이 실행하는 동안 브로커의 과도한 입출력으로 부하가 발생할 수 있기 때문이다.
따라서 브로커의 리소스 모니터링을 병행하여 로그 컴팩션을 사용하는 것이 좋다!
Reference
실전 카프카 개발부터 운영까지 - 교보문고
데이터플랫폼의 중추 아파치 카프카의 내부동작과 개발,운영,보안의 모든것 | | 이 책에서 다루는 내용 | - 풍부한 그림으로 알기 쉽게 설명한 카프카 내부 구조와 동작 원리 - 자바와 파이썬을
www.kyobobook.co.kr
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
'DevOps > Kafka' 카테고리의 다른 글
| [Kafka] 카프카의 보안 (1) | 2022.06.08 |
|---|---|
| [kafka] 카프카 버전 업그레이드와 확장 (0) | 2022.05.25 |
| [Kafka] 카프카의 모니터링 (0) | 2022.05.25 |
| [Kafka] 카프카 기본 개념 구조 이해하기 (0) | 2022.04.21 |


